Code Reviews
Code reviews check that your code follows various best-practices and standards. They also allow you to receive feedback while the code is still malleable. You should conduct a code review for each new merge request, and the reviewer should be someone experienced with the programming language of the project.
Note
It’s useful for the code reviewer to have expertise in the code’s scientific topic, as they may also identify any scientific inaccuracies. However, the code review is ultimately focused on the code, so these reviews should not fail on solely scientific grounds.
Software standards vary across different coding languages, and so the contents of a code review are ultimately at the reviewer’s discretion. However, there are various guidelines that reviewers should take into account. Please see the following sections for details:
Reference Code
The primary purpose of reference code is to document a reproducible workflow. As such, code reviews for reference code should ensure that an interested user with sufficient resources would be able to reproduce the workflow. Items in this review include:
Purpose
The project should indicate the code’s purpose (typically in a README file). This should state what the code does, and should describe any key outputs.
Environment
The project should document the computing environment required to run the code. Items in this documentation might include (but are not limited to):
Coding language
Required packages (both system-wide and language-specific)
Conda environments
Operating system
Docker images
The project should always document the versions of the coding language, packages, and and other items where versions are relevant. Installation instructions (or a link to instructions) should be included for any unusual or non-standard packages. Detailed installation instructions are not required for standard items, although they are usually appreciated by downstream users.
Instructions
Next, the project should indicate how to actually run the code. Typically, this is a step-by-step recipe for producing the intended output. This may include items such as navigating between folders, running specific commands, and any manual steps required between commands.
Clarity
Clarity is essential for workflow code, as it ensures that future users can understand what the code is doing. Here, we specifically refer to clarity within the code itself. Comments are a major component of clarity, and are recommended for complex code blocks more than a few lines long.
Clear names are another key component of clarity: a variable name should succintly state what the variable is, function names should describe what the function does, and class names should indicate what the class implements. Well written docstrings and (when relevant) type hints are also invaluable for improving clarity. For more complex packages, the layout of the package itself can also help improve clarity.
We emphasize that names should be both descriptive AND succint. With the exception of indices and some mathematical formula, you should not use single-letter variable names. Analogously, very long variable names should be avoided.
Cruft
Workflow code should document a workflow succinctly. As such, extraneous files and unused code should be avoided. We acknowledge that scientific codes often evolve in unexpected ways, and so a limited amount of unused code can be acceptable. However, excessive cruft should be avoided and is often a sign that the codebase requires some cleaning.
Security
Workflow code should be secure for a user who has read the documentation. If the code creates output files, then the project should indicate where those files are saved on the file system. If the code has a long runtime or uses large amounts of memory, then the project should document these effects. Finally, the code should avoid any obvious language-dependent security issues.
Rubric
The following is a suggested code review rubric for reference codes:
Item |
Pass |
Fail |
|---|---|---|
Indicates what the code does and any key outputs. |
The intended function is unclear. |
|
Reports the computing environment required to run the code. |
Environment has incorrect, partial, or no documentation. |
|
Step-by-step instructions on how to run the code. |
Unclear how to run the code. |
|
An interested user can understand what the code is doing and how it works. |
Unclear what is happening in the code. |
|
Minimal extraneous code and files. |
Excessive extraneous code or files. |
|
No obvious security issues. Reports the locations of output files. If relevant, long runtimes and/or high memory use is reported. |
Output file locations undocumented. Obvious security issues. Long runtime or large memory use not reported. |
Software Tools
Since software tools are intended for general reuse, they have a more comprehensive review rubric. Broadly, the items in this review can be split into two categories:
Documentation items ensure that other people can use the code, and understand what it is doing. Code-quality items ensure that code is implemented in a reasonable and efficient manner. Many scientists have differing levels of experience when it comes to designing code, and it is useful to allow code to improve iteratively over time. To accommodate this, the evaluation rubric is a spectrum, rather than a simple pass-fail.
Documentation
Broadly, documentation items check that a new user will be able to use your code. Ideally, a new user should be able to easily understand (1) how to install the code, (2) the code’s purpose, and (3) how to use the code to achieve that purpose. Items in this review include:
Installation
The greatest code is useless if no one can install it. As such, your code needs to have clear installation instructions. The best practice is for the code to use a standard package manager (e.g. pip, conda, Pkg, etc.) for installation. But less mature codes may provide a detailed list of dependencies and installation instructions instead.
API
The API (Application Programming Interface) tells other programmers how to use your code. An API should detail the inputs and outputs of each routine, and also note any changes made to a user’s file system or computational environment. APIs typically begin as docstrings and (if relevant) type hints, but can grow to include other formats. For example, as a Read the Docs site or a sphinx documentation set. Many other formats are also possible.
Narrative
Narrative refers to the ability for a new user to understand the workflow of your code. A quality narrative will clearly state the intended purpose of the code, and then demonstrate how to use the code to implement that purpose. When relevant, scientific theory underlying the code is also described.
For smaller projects, the narrative may be implied by the code itself. But the best projects will include tutorials/quickstarts/demos that illustrative standard use cases. These may appear as written documentation, but also include resources like Jupyter notebooks.
Code Quality
Code quality items check for a variety of coding best practices. Broadly, these check that the code runs in a clean and efficient manner, and also help other scientists extend and build off your work. High quality code is also easier to review, so these items also help a code review proceed in a timely manner. Items in this review include:
Clarity
Clarity refers to the ability for someone to read the source code and understand what is happening. Comments are a major component of clarity, and should be included for code blocks more than a few lines long.
Tip
Code blocks over ~8 lines often benefit from some light commenting.
Clear names are another key component of clarity: a variable name should succintly state what the variable is, function names should describe what the function does, and class names should indicate what the class implements. Well written docstrings and (when relevant) type hints are also invaluable for improving clarity. For more complex packages, the layout of the package itself can also help improve clarity.
We emphasize that names should be both descriptive AND succint. With the exception of indices and some mathematical formula, you should not use single-letter variable names. If you find yourself needing very long names to distinguish between related variables, this is a likely sign that the code should be more modular.
Modularity
Modularity is perhaps the most important item for code quality. This refers to the practice of breaking code into small/atomic/resuable/easily testable chunks. In general, improving a project’s modularity tends to improve the other code-quality items as well.
There are several facets to modularity. First, code should be general: it should not contain hard-coded variables. This includes both mathematical variables (such as model parameters), and operating system variables (such as file names). The best codes will have no hard-coded values, but a few hard-coded values can be permissible for complex, or less mature code bases.
A second facet of modularity is DRY code. DRY stands for Don’t Repeat Yourself. As a rule, repeated code should be avoided. Sections of copy-pasted code should be replaced with a function that implements the repeated routine. DRY code is easier to update and extend, as changes to the codebase are only needed in one location, as opposed to multiple repeated section. This also makes scientific code less error-prone, as it reduces the likelihood of changing one copied section without changing another. DRY code is also often more efficient, as it is easier to avoid running unnecessary repeated sections.
A final facet of modularity is extensibility. An extensible code base breaks apart long routines into smaller discrete pieces. This allows future scientists or developers to easily make changes to a workflow. It also provides natural break points for new functionality to plug-in to the existing code. Extensible code is also typically more efficient, as it allows users to re-run specific parts of a routine, rather than running the entire routine in multiple iterations. Finally, extensible code is typically easier to test, as there are fewer options passed to the discrete pieces.
Extensible code is analogous to, but distinct from, DRY code. In DRY code, routines are broken into atomic pieces to avoid repetition. In extensible code, the parts of a routine are broken into atomic pieces - even when there is no repetition.
Verification (Tests)
All code must be tested to demonstrate it performs as expected. The best codebases will do this using automated unit tests. Examples of automated unit testing frameworks include pytest (Python) and testhat (R), and there are many others. Less mature codebases may consider a few large tests that replicate published work.
A second important consideration is test clarity. It should be easy for a reviewer to understand:
What a test is testing,
How the test proceeds, and
How the test is validated
Test Coverage
A codebase must also demonstrate that tests are comprehensive. The best codebases will include tests for nearly all functionality in the software product. More limited tests can be acceptable, but must clearly test all core functionality of the code.
Many automated unit testing frameworks have tools to help assess test coverage. For example, the coverage tool or pytest-cov can be used to report the percentage of code lines covered by Python unit tests. Although this does not directly represent the core functionality of a module, it can be a useful proxy for reviewers.
Unused Code
Mature code should have minimal pieces of unused code. This includes unused variables, and portions of a routine that are not used in any circumstance. Most code editors include tools to identify unused lines, and you should remove such lines when they occur. This helps to keep code efficient (there are no unnecessary steps in a routine), and also improves clarity.
Developing codes may contain a few unused pieces of code, particularly if the unused pieces are likely to support future development. But these lines should either become used or removed as the code base matures.
Secure / Clean
Code should complete routines in a clean and secure manner. The exact meaning of this will vary by coding language and use-case, but some common considerations are described here.
Open Files: Many languages include methods that open a file for reading or writing. Once open, the computer can interact with the file, but the file cannot be used by other resources until it is closed. As such, code should ensure that opened files are closed by the end of a routine. This includes cases when a routine fails or produces an error - depending on the language, tools such as context managers or finally blocks can help ensure this behavior.
Temporary Files: It is not uncommon for a routine to store output in files for later use and processing. However, code should also minimize “file detritus” produced by a routine. If an output file is not needed for later processing, and is of no use to the end user, then the file should be deleted. On a similar note, code should ensure that all temporary files are deleted by the end of a routine to avoid cluttering the user’s file system.
Overwriting Files: When a routine saves an output file, the file could potentially overwrite an existing file on the user’s system. The best codes will warn the user when overwriting would occur, and/or include options to enable/disable overwriting behavior. However, it is also acceptable for less mature codes to write an output file to a standard name, so long as the location of the output file is well documented and apparent to the user.
Infinite Loops: Infinite loops occur when a loop cannot reach a stopping condition. This causes a routine to run without completing, causing the computer to freeze until a force-stop is enacted. Infinite loops most often occur when a while loop cannot reach a stopping condition. In some languages, a for loop can also produce an infinite loop if the loop iterator is altered within the loop. As a rule, code should not contain infinite loops. Avoid updating loop iterators within for loops. When a while loop is necessary, consider adding an explicit stopping condition after a certain number of iterations.
Rubric
The following is a suggested code review rubric for reusable software tools:
Documentation
Item |
Best |
Okay |
Unacceptable |
|---|---|---|---|
Standard, automated package management. |
List of dependencies AND Instructions for installing code/dependencies |
No installation instructions. Instructions are unclear or incomplete. Instructions don’t work. |
|
All inputs and outputs are described for all functions. |
Inputs and outputs are described for the core functionality. |
Inputs/outputs not documented. |
|
Several of the following: Tutorials Quickstart |
Standard use case is clear. If using realistic examples, input files/parameters are provided. |
Unclear how or why to use. Difficult to navigate. |
Code Quality
Item |
Best |
Okay |
Unacceptable |
|---|---|---|---|
Easy to understand what the code is doing. |
Some effort is required to understand the code. |
Code is very hard to follow. |
|
Minimal repeated code. Extensible design. No hard-coded variables |
Some repeated code. Long routines (less extensible). A few hard-coded variables. |
Extensively repeated code. Excessively long routines. Many hard-coded variables. |
|
Automated, modular tests. Tests are easy to understand. |
Large tests that reproduce published work. |
No tests. Tests are hard to understand. Tests fail. |
|
Nearly all functions tested. |
Core functionality is tested. |
Tests do not cover all core functionality. |
|
No unused code |
A few unused lines or variables. |
Many unused lines or variables |
|
Overwrite options or warnings. |
No temp files remaining. No obvious infinite loops or files left open. |
File detritus. Files that remain open. Frequent infinite loops. |
Gitlab How-To
To start a code review, navigate to the associated merge request and select the Changes tab:
Show tab
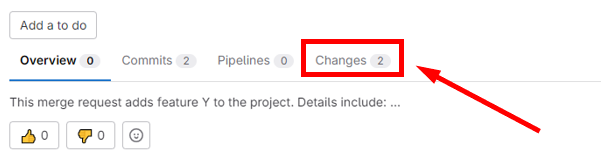
This will open a page showing all the differences between the review branch and the upstream repository. New lines are highlighted in green, and removed lines are highlighted in red.
Show Example
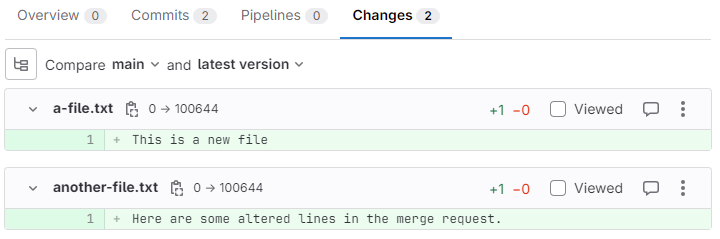
In some cases, it may be possible to code review from this tab alone. For other projects, it may be preferable to download the source files, and examine the updated repository in a code editor. The reviewer may use whichever method they prefer.
Once you have a review comment, locate the code in question within the Changes tab. Click the comment box on the left side of the line, or clikc and drag to leave a multi-line comment. This will open a comment thread for these lines. Leave the review comments, and click the Start a review or Add to review button at the bottom of the thread.
Show Example

Repeat this process for the remaining comments. Then, click the Finish review button at the bottom of the page:
Show Button

Leave a summary of the review for the author and click the Submit review button. This will fill the Overview tab with the contents of the review.
Show Example
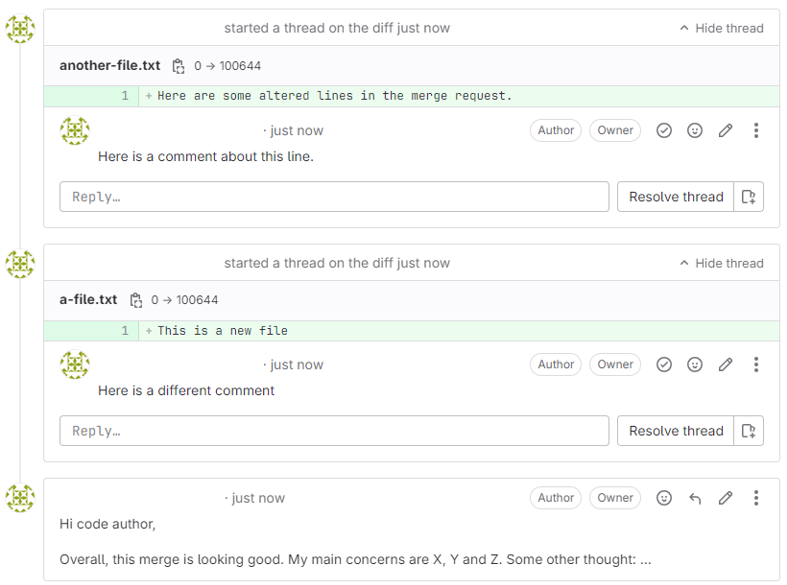
The code author and reviewer can now use this tab to conduct the review. The code author respond to the comments, make changes to the code, and mark comments as resolved using the Resolve thread buttons. The reviewer can discuss responses on these threads, open additional review comments, and unresolve threads as they see fit. This process is then archived with the merge request.
Once the reviewer is satisfied with the review reconciliation, they and the code author should follow the instructions for completing a merge request.